前々回、主成分分析と因子分析の違いについて、自分の主観を書いていくうえでPythonの matplotlib を使っていろいろ図を書いてきた。というか、単純な点数そのままの散布図と、標準化後の数値での散布図。
今回はRの勉強として、 tidyverse の ggplot を利用して同様の散布図を書くことを試してみようと思う。
環境構築
細かいバージョンなどは置いておくが、今回もR Studioで renv を使いつつ環境を用意してみる。以前の記事と同様に、R StudioでNew Projectを作り、新しいディレクトリを作成する。
何よりもまず tidyverse パッケージのインストール
install.packages("tidyverse") #初回のみ実行
では、 tidyverse パッケージを読み込んでみようと思う。
library(tidyverse)
すると表示としては
── Attaching core tidyverse packages ─────── tidyverse 2.0.0 ── ✔ dplyr 1.1.4 ✔ readr 2.1.5 ✔ forcats 1.0.0 ✔ stringr 1.5.1 ✔ ggplot2 3.5.2 ✔ tibble 3.3.0 ✔ lubridate 1.9.4 ✔ tidyr 1.3.1 ✔ purrr 1.1.0 ── Conflicts ───────────────────────── tidyverse_conflicts() ── ✖ dplyr::filter() masks stats::filter() ✖ dplyr::lag() masks stats::lag() ℹ Use the conflicted package to force all conflicts to become errors
という感じで出てくる。Pythonなど他の言語を使っていて、正直 Conflicts 大丈夫か??と思ってしまうが、結論としてはあまり気にしなくても良いとのこと。まあ、そうGeminiが言っていることを、まあ確かにねと読んだだけではあるが…笑 まあ、現状困っていないので後回しで。
よくはないのだが、関数名などが重なっているパッケージがあるので、その場合は dplyr::filter() や stats::filter() と宣言して呼び出すことで動くようだ。
データの読み込み
では、実際にCSVデータを読み込んでみよう。
data <- read_csv("../../01_factor-analysis/data/factor_analysis_test_data.csv")
データは以前利用した成績的なデータのCSVファイル。
今回は tidyverse パッケージをインストールした際にインストールされた readr パッケージの read_csv 関数を利用する。なかなか、本物のドキュメントに辿り着けずむず痒かったが、この辺りの記事を参考にした。
散布図
では、前回同様、 算数 と 理科 の点数を散布図で書いてみようと思う。コードはこのようになるようだ。
# 散布図の作成 # ggplot()で描画設定を開始 # aes()でX軸とY軸に使う列を指定 # geom_point()で散布図を描画 ggplot(data, aes(x = 算数, y = 理科)) + geom_point() + labs( title = "算数と理科の得点の散布図", x = "算数", y = "理科" ) + theme_minimal()+ theme( text = element_text(family = "Hiragino Kaku Gothic ProN"), # 日本語フォントの適用 plot.title = element_text(hjust = 0.5), # ここでタイトルを中央に揃える axis.title.x = element_text(hjust = 0.45), # x軸ラベルを中央に揃える axis.title.y = element_text(hjust = 0.5) # y軸ラベルを中央に揃える )
出力されたグラフはこちら。
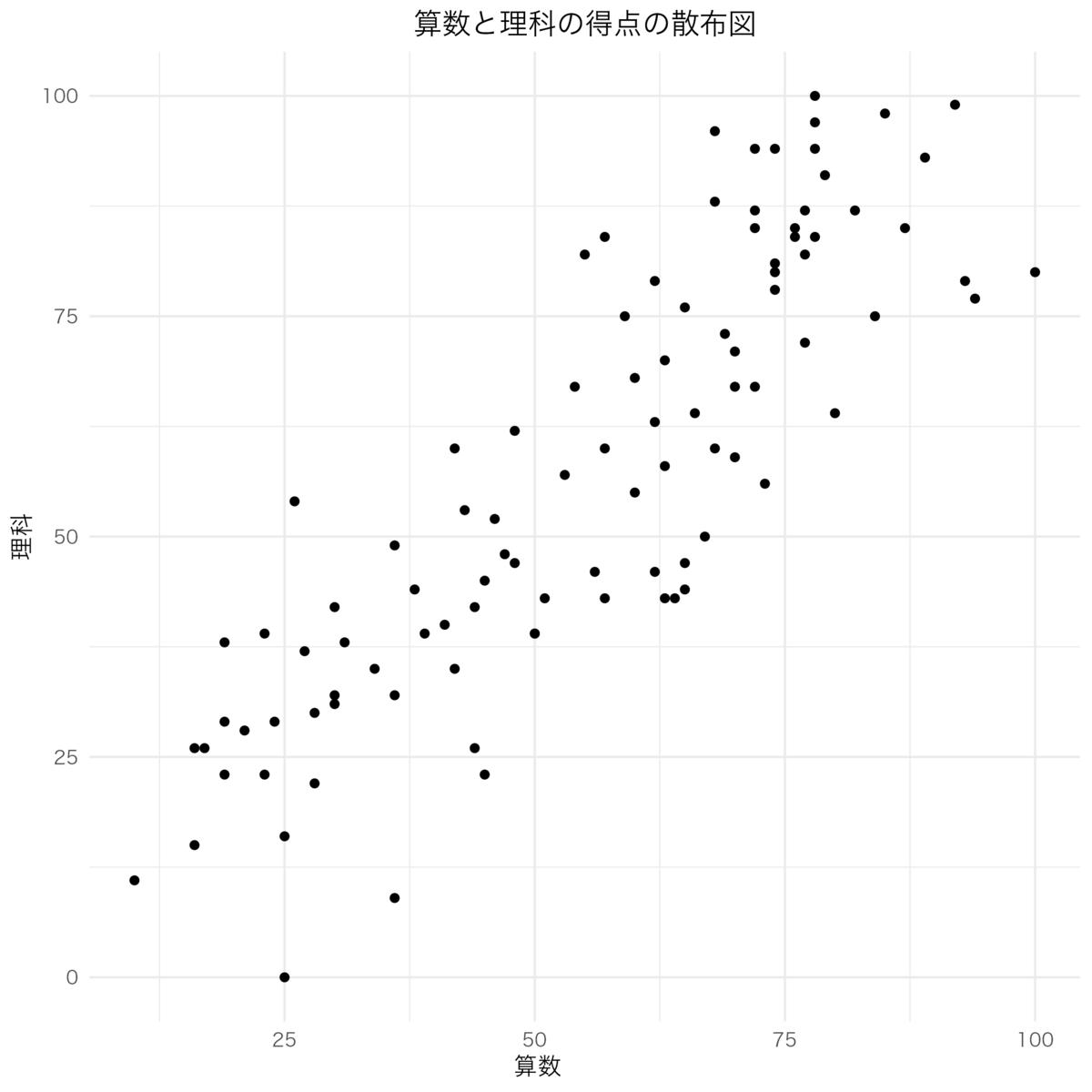 (背景透過の図のせいで見づらかったらごめんなさい)
(背景透過の図のせいで見づらかったらごめんなさい)
まあ最初の、 ggplot(data, の部分は関数の引数としてわからんでもない。
次の aes() て何だろうと思ったが、aestheticsの略語の関数のようで、X軸のデータやY軸のデータを指定するようだ。aestheticsは美的という意味の言葉らしい。
+が何を意味するんだ、となったが、「レイヤー」を追加していくことを指すようだ。まあ、上から順に書いていく、ということを指しているのかと思う。まあ確かに、次からは散布図のプロット自体だったり、タイトルと軸の名称などが並んでいく。
geom_pointは散布図を書く関数。他にも geom_bar だと棒グラフ、 geom_line だと折れ線グラフになるようだ。まあ、つまり、 point なので、点を描画する関数ということで良いだろう。
theme_minmal() は描画テーマを指定する箇所。他にもいろいろテーマは選べるようだが、現状こだわりは無いので、Geminiで調べた時に最初に出てきたものをとりあえず選んだ。
theme() はけっこう困った部分。今回は element_text() でテキスト系の設定をいくつかいじってみた。デフォルトのフォントが何かは確認していないが、欧文フォントしかないものだったようで、日本語フォントを含むヒラギノを今回は選択した。Windowsの場合は適宜、インストールされているものを探ってもらえれば良いのかと思う。
次に、 各種 title について表示位置の調整をした。 hjust にて水平方向への位置を調整できるようで、基本的には 0.5 で真ん中になる。ただ、おそらく横軸が 12.5から開始されていることもあり、 0.5 だとうまく真ん中に合わなかった。まあ基本としてはそれよりも横軸の範囲を 0〜100にすべきとは思ったが、グラフ自体のタイトル位置がデフォルトでは 0.5 ではなかったようで思った位置に出なかったこともあり今回この指定をしてみたのでよしとする。
また、 hjust vjust は文字についてはフォントの向きをベースに考えるようで、今回で言うと 理科 の方向は vjust にしたくなるがそうではなく、 hjust で調整することがわかった。
ファイルに書き込む場合は以下のようなコードになる。
# 散布図の作成 # ggplot()で描画設定を開始 # aes()でX軸とY軸に使う列を指定 # geom_point()で散布図を描画 # プロットオブジェクトを変数に格納 p <- ggplot(data, aes(x = 算数, y = 理科)) + geom_point() + labs( title = "算数と理科の得点の散布図", x = "算数", y = "理科" ) + theme_minimal()+ theme( text = element_text(family = "Hiragino Kaku Gothic ProN"), # 日本語フォントの適用 plot.title = element_text(hjust = 0.5), # ここでタイトルを中央に揃える axis.title.x = element_text(hjust = 0.45), # x軸ラベルを中央に揃える axis.title.y = element_text(hjust = 0.5) # y軸ラベルを中央に揃える ) # グラフを画像ファイルとして保存 ggsave("../fig/11_r_scatter.png", plot = p)
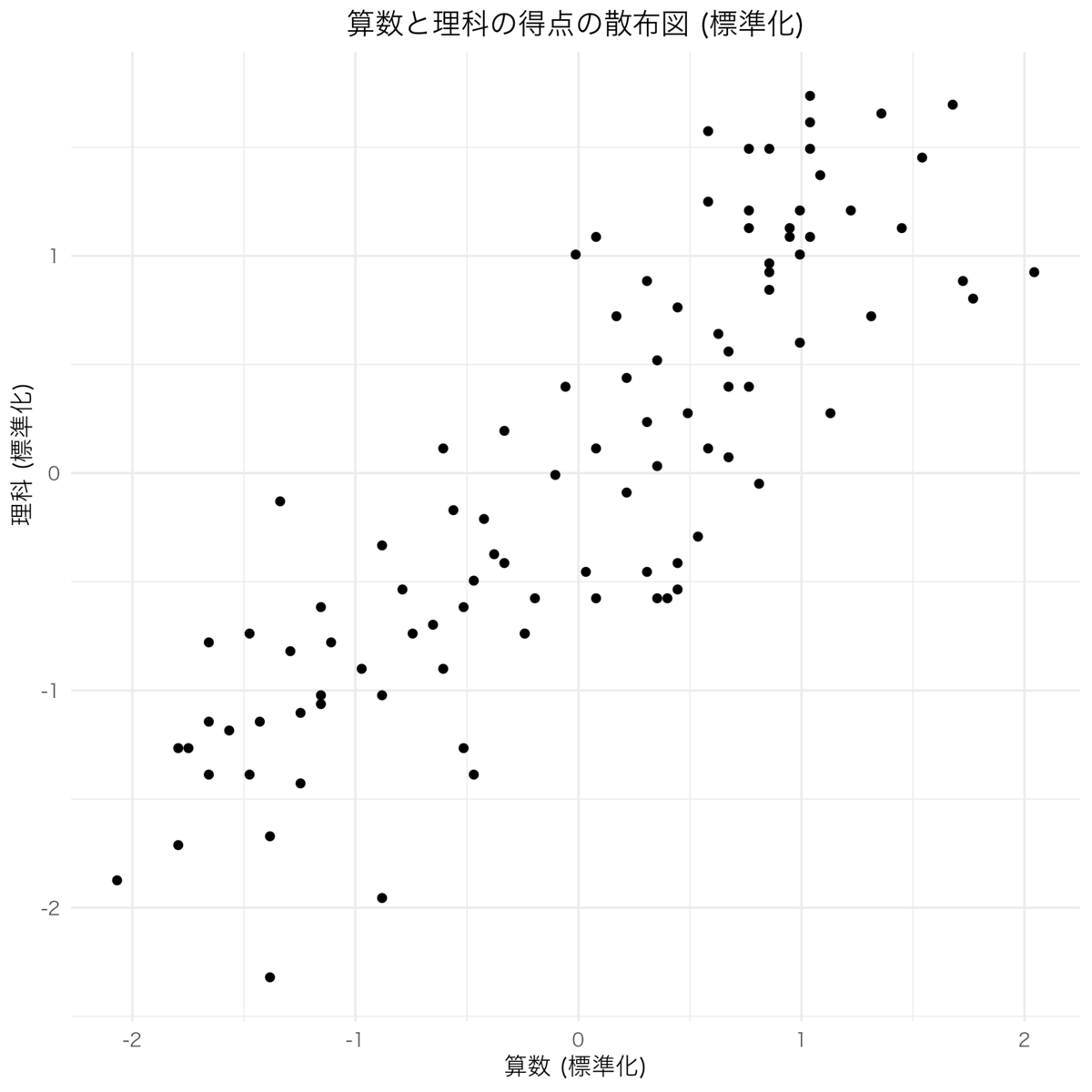
標準化
続いて、各点数を標準化し、平均0、標準偏差1にしてみる。早速コードは以下の通り。
# データの標準化 # mutate()で新しい列(算数_std, 理科_std)を作成 # scale()で各列の値を標準化(平均0, 標準偏差1) data_standardized <- data %>% mutate( 算数_std = scale(算数), 理科_std = scale(理科) )
まずは簡単なところから、 scale() 関数で簡単に標準化が可能。おそらく、Rの標準関数だと思われる。
%> て何やねん。というところだが、こちらはパイプ演算子と呼ばれるもので、 dplyr パッケージに入っている関数というか、のようだ。先ほど、conflict出してたやつ。何となく、自分がPython等で右から左というか内から外に慣れてしまっているが、、、Rのパイプ演算子は左のデータを右に渡すもののようだ。まあ、形がそうか。つまり、次の mutate() 関数に data を渡していることになる。
mutate() 関数は dplyr パッケージに含まれる関数で、データフレームに新しい列を追加する関数のようだ。何となく、変数名がindexになって、中身のリスト的データが列データとして入るのだな、と理解できる。
では、標準化したデータを元にグラフを書いてみる。コードは省略するが、Githubには上げる。
まとめ
今回は、前回Pythonの matplotlib で書いた散布図について、Rの tidyverse パッケージ、その中の ggplot を使って散布図を書く方法を確認した。まあ、この程度であれば、Pythonで良くないか?というのが、今の感覚ではあるのだが…笑
%>% や + など、Rは左から右にという考え方が多そうだ。確かにわかりやすい気もするし、何となく () で囲われていないことの違和感というか、自分としては再帰処理的な方がプログラミング言語のイメージに合っているのでまだ違和感がある。この辺は使っているうちに「Rすげー 。超便利」となるのか、うーーんとなるのか笑 まあ使ってみてだなぁ。
参考資料
自分が慣れていないのだと思うが、なかなかR関係は公式ドキュメントをうまく見つけられない…Githubリポジトリなどがあると見つけやすいのだが…多分あるのだろうが、見つけ方が下手なのだと思う。