前回、ローカルのOCRやLM Studio経由で文字認識を試してみた。今回は追加としてテストしたYomiTokuを紹介する。
はじめに
YomiTokuはMLism株式会社が開発しているOCRになる。先日の文字認識の比較対象として、Tesseractとは別のOCRを探していて見つけた。見つけた記事の検証は行政的な出版の文書を対象としていて、手書きではないため対象にするか悩んだが、試してみたところ高精度、かつレイアウトの分析も素晴らしく感じたので紹介したい、となった。
ライセンス的には個人利用や検証目的は無償で可能な CC BY-NC-SA(非営利目的)。商用利用したい場合は別途商用版を契約して利用する必要がある。商用利用もローカル版もあるが、AWS上で動作可能なものはAWSのマーケットプレイスにもある。
ブログ記事での紹介は商用か?悩んで確認してみたが、無償の範囲で問題ないと確認できたこともあり、安心して記事にしている。
環境
- MacBook Air M2 2022
いつもの内容にはなるのだが。
GPUを利用すると高速化できるようだ。PyTorchを使っているように見えるのでMPSで高速化できそうだが…下にも書いている通り、CPUで動作させて確認した。数年前モデルもM2のCPUでも十分早い印象を持った。
検証用画像
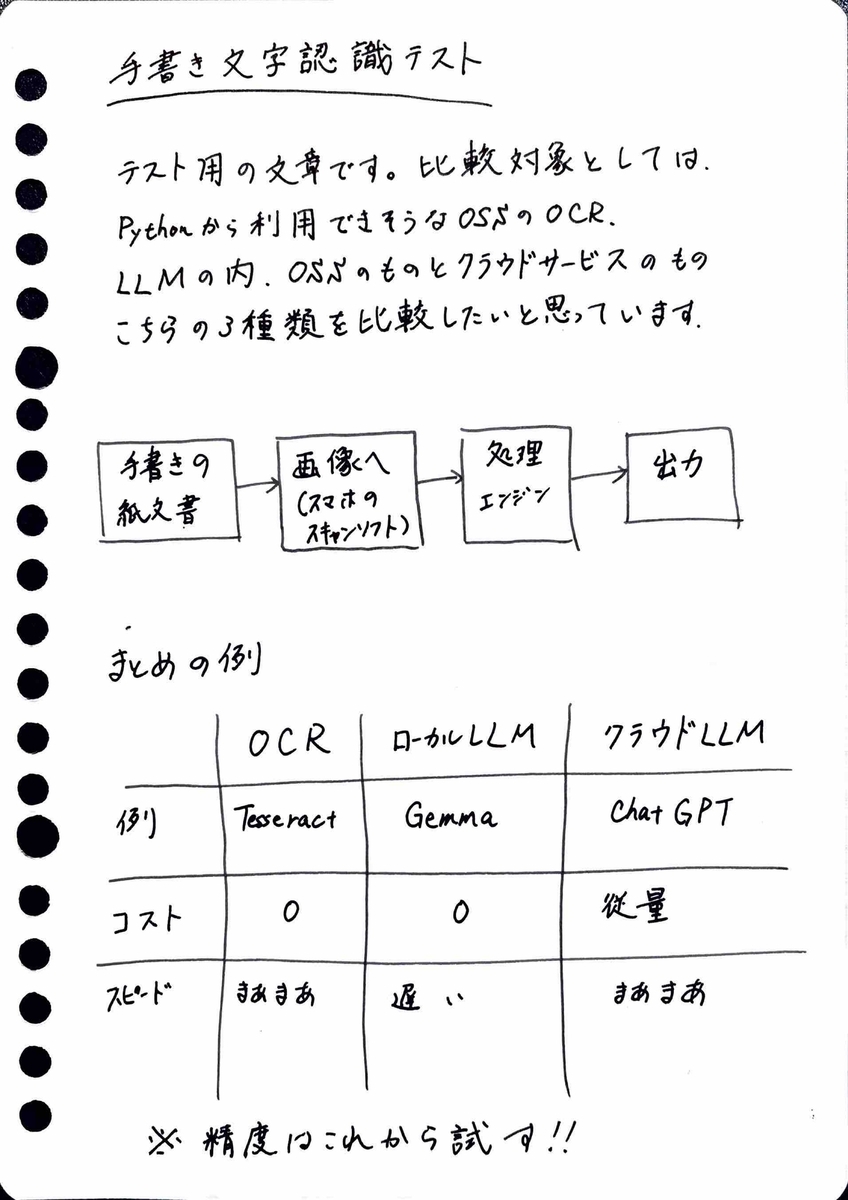
前回と同じ画像を用いて検証した。
検証
まずは導入について、今回自分は pip を利用してインストールした。自分が利用したPythonは 3.12.11 だった。
pip install YomiToku
pip 以外に uv でインストールする方法も用意されている。 uv についてはローカルサーバーをMCPサーバーとして、別のLLMなどから利用する方法も紹介されている。
あとは以下のコマンドを自分は試した。
YomiToku {画像ファイル名} -f md -d cpu -o {出力フォルダ名} -v --figure
各コマンドの詳細オプションは公式のリポジトリなどを確認してもらうのが正確だし早いとは思う。今回利用したのは以下。
-f: 出力形式のファイルフォーマット。今回はMarkdownのmdを選択したが、JSONなど他のフォーマットも選択できるようだ。-d: 実行するデバイス。今回はcpuとした。-o: 長いオプションは--outdir。つまり出力フォルダをここに書くよという指定。書かない場合、現在のフォルダだったような気がする。存在しないフォルダの場合、新規で作成してくれる。-v: 解析結果を可視化した画像を出力してくれる。あとで貼ろうと思う。--figure: これが結構面白い。ある意味VLMと違う結果を出してくれる形になるが、もうここは「図だな」、「画像だな」と判断した箇所について画像として切り出して出力してくれる。こちらもあとで貼ろうと思う。--ignore_line_break: 今回は指定していないが、改行位置を画像のままとするか無視するかというオプション。付けたほうが便利になるタイミングも多いような気もする。今回はテストということもあり、そのままとしてみた。
では結果へ。
Markdown出力
# 手書き文字認識テスト テスト用の文章です。比較対象としては、<br>Pythonから利用できそうなOSSのOCR.<br>LLMの内.OSNのものとクラウドサービスのもの<br>こちらの3種類を比較したいと思っています <img src="figures/_IMG_4454_p1_figure_0.png" width="200px"><br> まとめの例 |例|OCR|ローカルLLM|クラウドLLM| |-|-|-|-| ||Teseract|Gemma|Chat GPT| |コスト|0|0|従量| |スピード|まぁまあ|遅い|まあまあ| ※精度はこれから試す \!\!
正直めちゃくちゃ感動した笑
レイアウト可視化画像
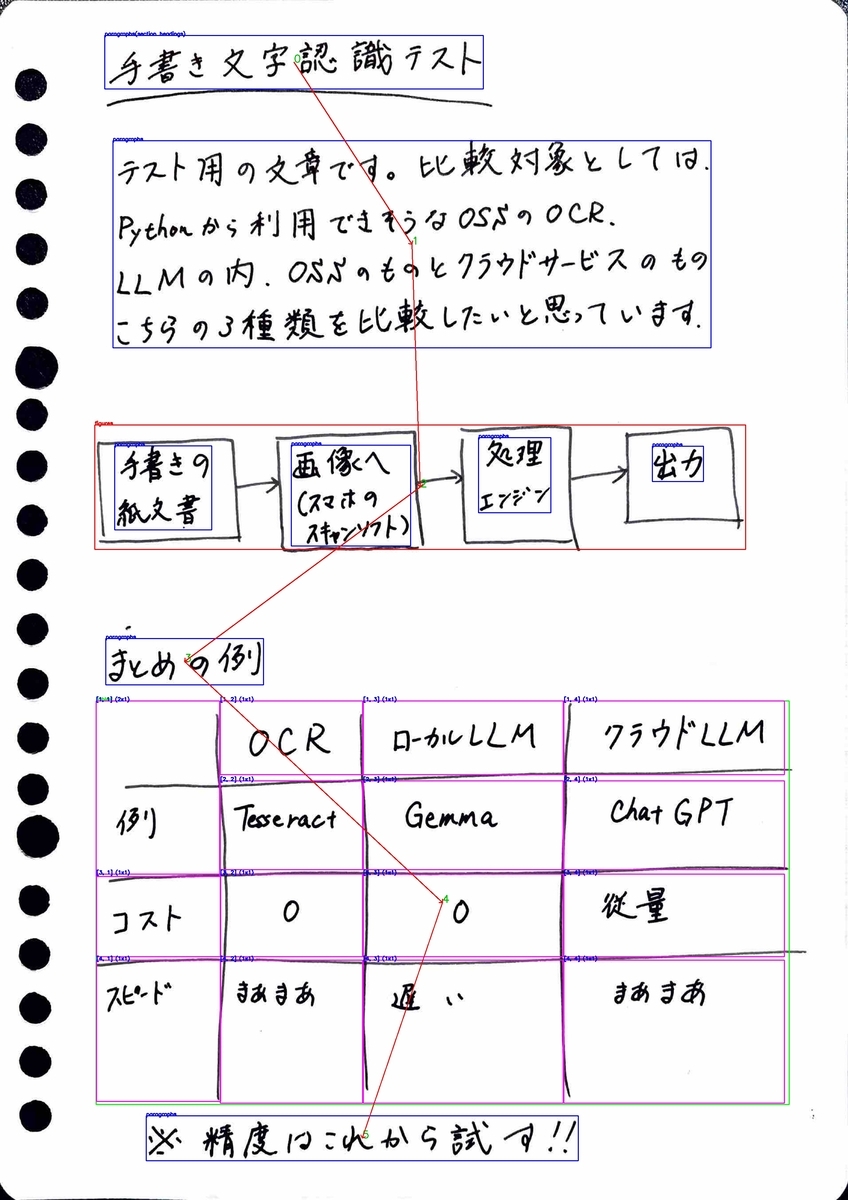
表のところなども結構感動する可視化。逆に認識してもらえないようだと字が汚すぎるのだろうかと考えるレベル笑
図形切り出し
自分の手書きのうち以下の箇所を図形として認識して、画像を出力してくれた。

前回の目標としては、例えばMermaid.jsのフローチャートなどで書いて欲しかったという思いはあるものの、逆に図形位置をきちんと見分けていることは素晴らしい動きではあると思う。
その上でOCR内容の画像も用意されており以下。

図形部分の文字も当たり前かもしれないが、文字認識はしている。
まとめ
今回はYomiTokuを紹介した。他のものとの比較については前回のブログに内容を追加している。
日本語を確実に扱えて、使いやすいOCRとしては驚くレベルだった。今回深掘りはしなかったが、MCPも使えるようなので、AIエージェント的なものから自走的に利用する場合も選択肢に入るかもしれない。
OCRに特化した内容だと、あとはGoogle Cloudのものも気にはなっているのだが、API利用料が気になり試していない。まあ、頻度低い際には従量課金なのがメリットではあるのだが。。
完全に個人の趣味レベルで利用する場合、ライセンス的にも問題ないと思うのでかなり有力になってくると思う。一方で、仕事で利用する場合は、AWSバージョンの利用を考えるなども含めて、検討が必要となってくる。
参考資料
- YomiToku: YomiToku自体のページ。Github Pagesを利用しているようだ。
- yomitoku: 公式のリポ: 公式のリポジトリ。
- MLism会社概要 | MLism 作成している会社さん。: 作成している会社さん。