これまであまりGoogle Colabを使ってこなかった。理由としては、Google Driveとの連携が必須と勘違いしており、事前学習したモデルなど保存できないじゃないか、と思っていたため。友人などから、一時保管の容量があるということを聞き、試してみることにした。
せっかくなので容量を食いそうな動画生成のモデルが良いと考え、画像から動画を生成するモデルを検索してみたところ、新しめなものでMagic Animateが見つかったので試しに動かしてみた。
Magic Animateについて

Magic Animateのデモページのgif動画のリンク。
左の”画像”と、真ん中の”動き動画”を入力すると、右の動画を出力するよ、というAIモデル。
FAQを見るとどういうものかはよくわかると思う。
Magic Animateとは何ですか?
Magic Animateは、ByteDanceが開発したAI駆動のアニメーションツールで、静止画をリアルなアニメーションに変換します。
と書いてある通り、ByteDanceはTikTokなどを運営する会社。確かにTikTokで使えそう。(TikTok使ったことなくイメージでしゃべっているが)
githubのリポジトリを見ると、CVPR2024と書いているので、2024年に学会発表したものなのだろう。arXivへの投稿は2023年のようだ。まあ、中身を読む分にはCVPRの本物が太っ腹なことにOpen Accessなので、それを読めば良いと思う。
Google Colabでのコード
では本題のGoogle Colabで動くコードについて紹介する。
まずは、ランタイムのタイプを変更 -> ハードウェアアクセラレータをGPUへ。自分の場合は、無料版なのでT4を選択した。
次に、githubのコードをクローンしてくる。
!git clone https://github.com/magic-research/magic-animate
次にクローンしてきたディレクトリに移動する。 cdコマンドは %をつけるのがまだ慣れない。 %のものと !のものの区別を勉強したい(普通のJupyterもそうなのかもだが…)
%cd magic-animate
次に requirementx.txtをもとに必要なライブラリをインストールする。
!pip install -r requirements.txt
この際に各ライブラリのバージョンの相性についてエラーが出るが無視して良い。どうしても気になるなら、むしろ解決にはなっていないが、以下のコマンドでエラーを出さない(無視しているだけだが)ようにはできる。
!pip install --force-reinstall --no-deps -r requirements.txt
まあ、エラーを無視すればいいだけなので、そのまま pipでインストールするバージョンで良いと思う。
まあまあ量があるので地道に待つ。自分の場合は実行に5分1秒かかった。

おそらくランタイムの再起動を求められる。再起動するしかないはずなので再起動する。
再起動後は現在開いているディレクトリが /contentに戻ってしまう。 cdで magic-animate/ディレクトリへ。
%cd magic-animate/
次に事前学習したモデルをダウンロードしてくる。まず以下2つをダウンロード。
!git clone https://huggingface.co/stabilityai/sd-vae-ft-mse /content/magic-animate/pretrained_models/sd-vae-ft-mse/ !git lfs clone https://huggingface.co/zcxu-eric/MagicAnimate /content/magic-animate/pretrained_models/MagicAnimate/
次に stable-diffusion-v1-5をダウンロードしてくるのだが、一苦労必要。まずは、 pretrained_models/へ移動し、 stable-diffusion-v1-5/ディレクトリを作成する。
%cd pretrained_models/
!mkdir stable-diffusion-v1-5/
作成した stable-diffusion-v1-5/へ移動
%cd stable-diffusion-v1-5/
内部でstable-diffusionを利用するようなので、学習済みモデルを wgetでダウンロードしてくる。
!wget -P scheduler https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/scheduler/scheduler_config.json !wget -O v1-5-pruned-emaonly.safetensors https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors !wget -P text_encoder https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/text_encoder/config.json !wget -P text_encoder https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/text_encoder/pytorch_model.bin !wget -P tokenizer https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/tokenizer/tokenizer_config.json !wget -P tokenizer https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/tokenizer/merges.txt !wget -P tokenizer https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/tokenizer/special_tokens_map.json !wget -P tokenizer https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/tokenizer/vocab.json !wget -P unet https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/unet/config.json !wget -P unet https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/resolve/main/unet/diffusion_pytorch_model.bin
元のディレクトリに戻る。
%cd ../../
この後実行へ移るのだが、もとの設定yamlファイルだと、5つの動画を作る設定になっていて時間がかかる。設定ファイルである configs/prompts/animation.yamlを変更し、出力を1つだけにする。
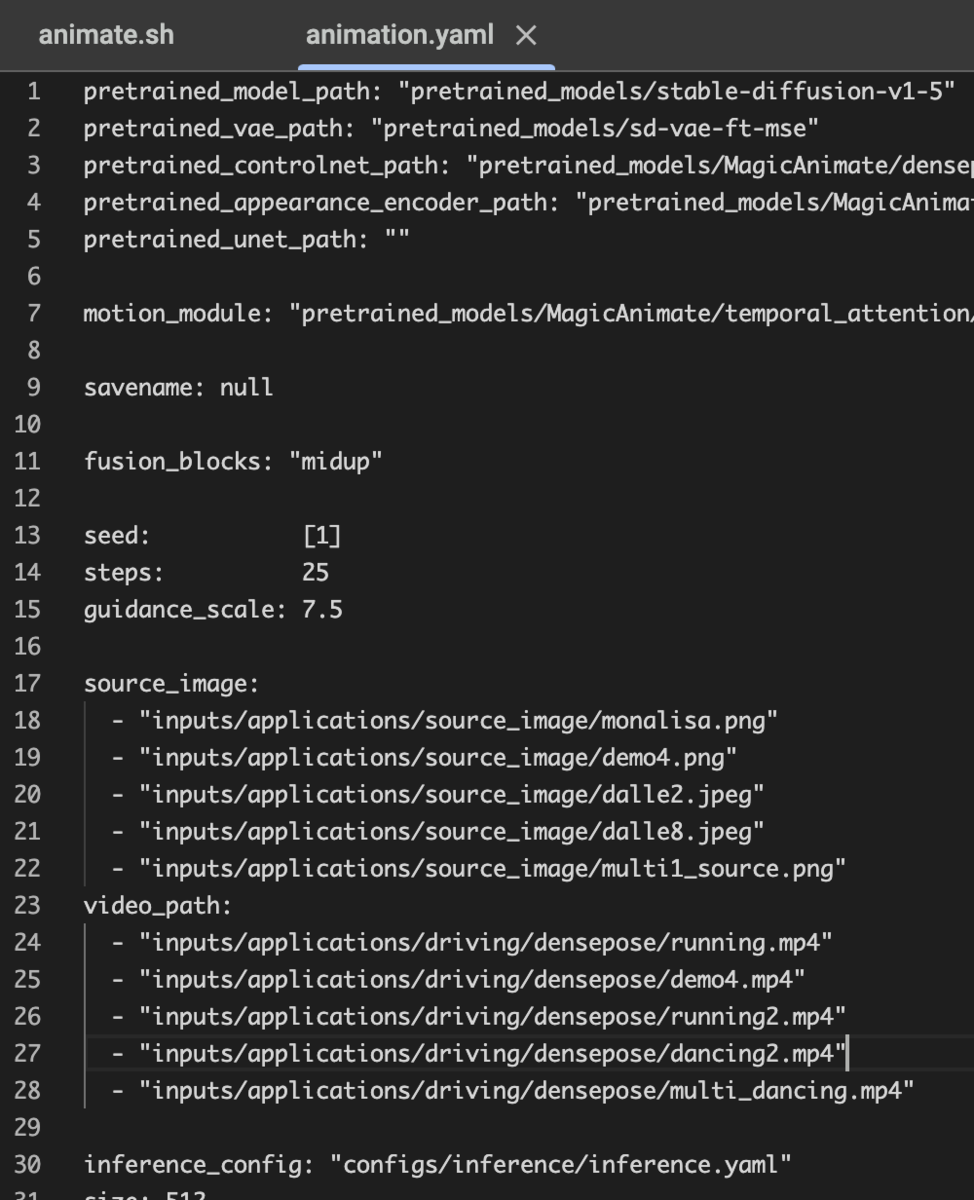
こちらをこのように変更。
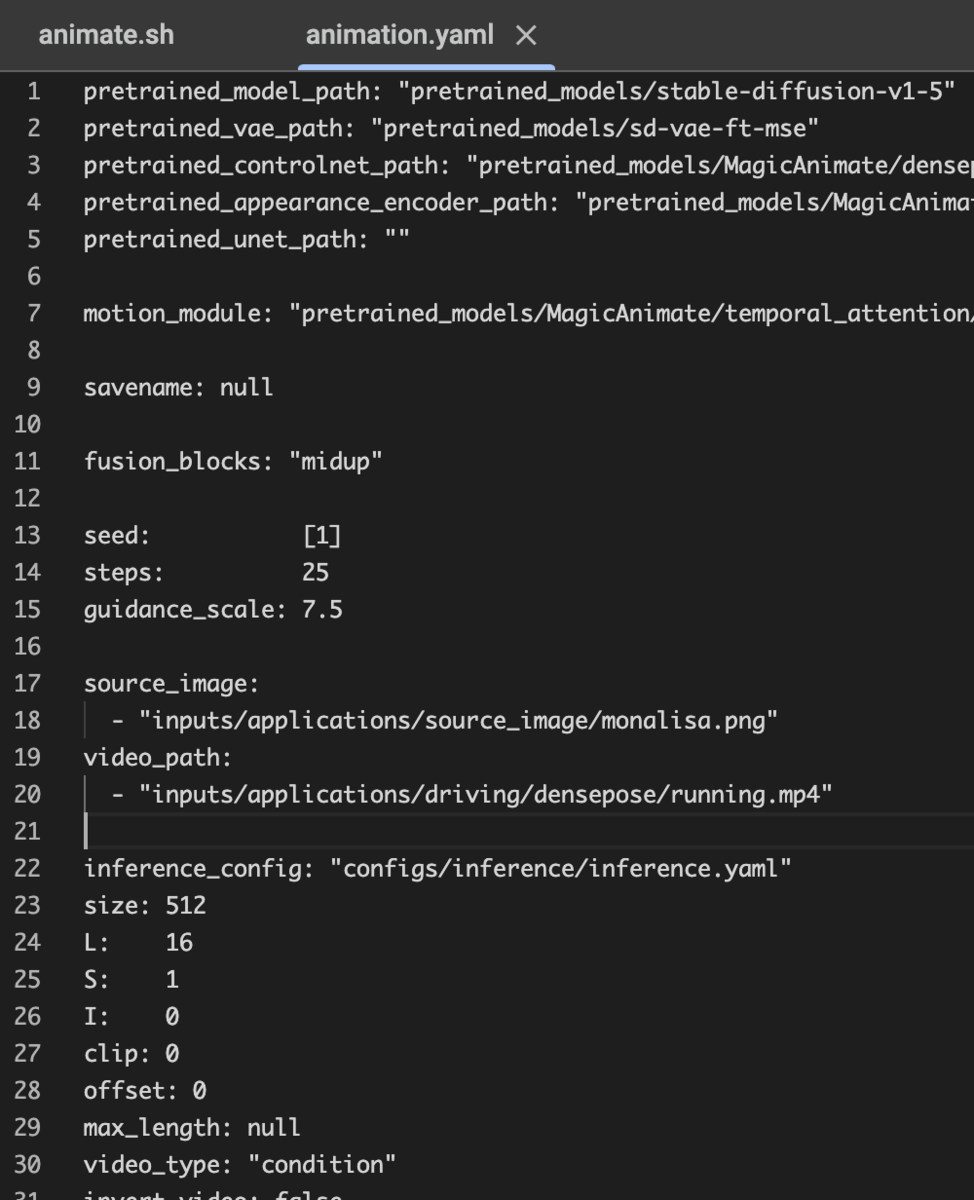
あとはスクリプトを実行すれば動画が生成される。
!bash scripts/animate.sh
T4だと、実行時間は9分14秒。

出力されたものがこちら。

せっかくなので、いらすとやのピーターパンおじさんも入れてみる。透明度情報がある画像はうまく処理できないようで、面倒だったのでとりあえずJPEGにしてしまった。

右上のせいでうまくいかなかったらご愛嬌のつもり。出力された動画がこちら。

うん。言葉にできない。が、すごい。
まとめ
今回はじめてGoogle ColabでDeep Learning的なモデルを動かしてみた。最初から、少しハードルが高いものを動かしてしまった気がする笑 今後はいわゆるよくあるWhisperとか、今回も出てきたStable Diffusionとかを動かしてみてもいいかな、と思っている。
また、少し調べるとGoogle ColabでFastAPIを動かすなどもできそうだった。まあどこまでOKな方法なのかはよく分からないが笑
また、まだ慣れていないところもあり、T4を動かしているものの本当に動いているのか謎な時もあった。有料版だともっと使えるGPUも増えるらしいので、お金を出して遊んでみてもいいかもしれない、とも思っている。